
ESC – TechBlog
techblog.esc.de
Aktuelles aus unserer Technik - Q2 / 2024
Seit Check Point im Juli 2023 R81.20 zum Magnum Opus seiner bisherigen Entwicklung erklärt hat und im April 2024 bereits R80.40 ausläuft, steht für viele Kunden die R81.20 Migration samt Konsolidierung & Optimierung der Security Policy an. Wir setzen diese Projekte erfahren & kundenspezifisch um.

Es gibt ja so schöne Begriffe, wie Single Point of Failure, Bottleneck, Standalone, Unmanaged, Lokales Logging, Lokales Management, Never touch a running system. usw. Schon einmal gehört? Hoffentlich nicht im Umfeld Ihres Netzwerk-Perimeters!
Das Gegenteil davon sind Redundanz, Fehlertoleranz, Distributed Deployment, zentrales Management, Monitoring & Logging, gemanagte Switche, getrennte Stromkreise, Aktualität aller Soft- und Hardwarekomponenten. Wow!
Letztere Begriffe sollten eigentlich die Ziele jeder IT-Verwaltung sein. Oftmals zeigt uns die Praxis jedoch, dass nur die Komponenten von zentraler Bedeutung (Firewall, Proxy, Mailserver, ESX-Server, usw.) redundant ausgelegt werden, um dann an einfachen, teilweise ungemanagten, Switchen und Routern ihr Dasein zu fristen. Eine konsistent geplante und stringent umgesetzte Redundanz zur Erhöhung der Stabilität und Verfügbarkeit aller Netzwerkkomponenten betrachtet jedoch alle an der Netzwerkstruktur beteiligten Komponenten. Das beinhaltet die logische Konzeption eines verteilten (Distributed) Systems bis hin zu getrennten Stromkreisen für die redundanten Netzteile.
Hilfsmittel, wie Farbcodes und Namenskonventionen, sind dabei nicht nur erwünscht, sondern aus unserer Sicht unabdingbar, um administrative Fehler schon im Planungsprozess, als auch bei der späteren Umsetzung & Instandhaltung, vermeiden zu helfen und zwischen allen Beteiligten klar zu definieren, wie und wo etwas aufgrund welcher Konzeption konfiguriert ist.
Vorab sollte daher immer ein konzeptioneller Netzplan zur allgemeinen Veranschaulichung erstellt werden, bei welchem auch die Switche geclustert bzw. gestacked sind. Denkbar wäre noch HSRP für die ISP-Router und LACP für die Bündelung von physischen Netzwerkverbindungen.
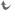 Back to top
Back to top